 English
English Español
EspañolHelp do Replica
Cadastro de Localidades
O cadastro de localidades tem por objetivo auxiliar
distribuição dos processos automáticos para diferentes máquinas que utilizam-se de uma
mesma base de dados. Desta forma, o usuário poderá especificar quais processos serão
executados em um servidor específico sem que estes processos sejam executados pelos
demais servidores que utilizam-se desta mesma base de dados.
Para melhor exemplificação, iremos supor que um determinado cliente
possui uma base de dados corporativa, onde existem vários servidores que executam
processos distintos: um servidor para o banco de dados (servdados), um servidor de
arquivos (servarq) , um servidor de aplicações (servapl) e um servidor que controlará
processos de acesso off-line (servoff) (no caso do cliente possuir a solução de
Ronda Senior).
Agora imaginemos que esta mesma base de dados (presente em servdados) necessitará
executar processos de acerto de data/hora e coleta off-line, sendo que estes processos
precisam ser executados em servoff, pois os relógios e os aplicativos para acesso aos
mesmos estão localidados neste servidor. Os demais processos como a emissão de
relatórios gerenciais e a execução do cálculo da apuração (no caso do cliente
possuir o módulo de Controle de Ponto e Refeitório), poderiam ser executados no servidor servapl, visto que este já é
um servidor de aplicação e é uma máquina mais potente.
Na situação atual, a divisão destes processos automáticos não seria possível sem que
estes processos fossem cadastrados em diferentes bases de dados, pois não havia uma
divisão de tarefas a serem executadas por servidor (localidade). Isto significa que se
fossem instalados 2 (dois) Agendadores (um em servoff e outro em servapl), todos os
processos cadastrados seriam executados nos dois servidores, o que ocasionariam erros nos
processos off-line em servapl e erros nos processos de relatório em servoff. Desta forma,
o cliente era obrigado a centralizar todos os aplicativos necessários e demais processos
automáticos em um único servidor, que no nosso exemplo seria servoff, devido à
existência do aplicativo de acesso ao relógio off-line.
Para resolver este tipo de problema e evitar a superutilização de um
determinado servidor, foi criado o conceito de localidades dos processos automáticos. As
localidades consistem em um cadastro simples, o qual será utilizado juntamente com o
cadastro dos processos automáticos do Agendador. Desta forma, para o exemplo anterior,
poderão ser cadastradas duas localidades: Localidade 1 Portaria, que
seria utilizada para os processos off-line, e Localidade 2 Recursos
Humanos que seria utilizada para os processos de relatório e cálculo da
apuração.
Da mesma forma, os aplicativos Agendador presentes em cada um dos
servidores (servoff e servapl) precisariam ser configurados para utilizar os dados da
localidade correspondente. Esta configuração deverá ser feita através do arquivo de
inicialização (HTTPCFG.INI) presente no diretório do Windows de cada máquina,
incluindo a cláusula LOCALIDADES=1 para servoff e LOCALIDADES=2 para servapl.
Exemplo do arquivo HTTPCFG.INI da máquina servoff:
...
[AGENDADOR]
VERIFICACAO=180
ARQUIVOLOGAGENDADOR=\\roque\public\LOGAGENDADOR.LOG
PERIODICIDADELIMPEZA=600
LOCALIDADES=1
...
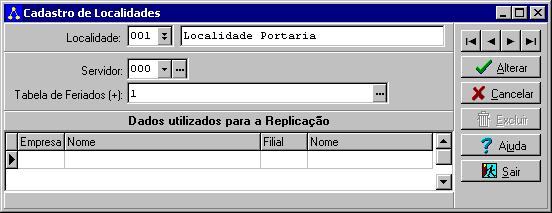
Observação: O detalhe
desta funcionalidade é que a mesma ainda não foi implementada. Caso o cliente veja que
esta implementação é realmente necessária, basta entrar em contato com o suporte da
Senior solicitando a implementação da mesma.
Para a execução dos processos automáticos, somente serão utilizados
o código da localidade e a abrangência da tabela de feriados. As demais informações
serão de uso do aplicativo Replica.
Como pode ser notado, o cadastro de localidades possui a abrangência
de feriados. Para este campo, deverão ser cadastradas as tabelas de feriados que deverão
ser consideradas para os processos presentes nesta localidade. O motivo para a presença
desta campo é bastante simples.
Imagine que você tenha cadastrado um processo automático de leitura de marcações que
somente poderá ser executado em dias úteis. Desta forma, o aplicativo Agendador
verificará, antes da execução do processo, se o dia atual é um dia não útil
(sábado, domingo ou os feriados cadastrados na base de dados do Sistema Gestão
de Pessoas). Então,
como o Agendador verifica se o dia atual é um feriado, para a verificação deste será
levado em consideração a abrangência de feriados informada no cadastro de localidades. A informação da abrangência é útil para as empresas que possuem
uma base centralizada e várias tabelas de feriados cadastradas. Isto significa que para
uma localidade poderá ser feriado, mas não para outra localidade, o que será levado em
consideração pelo Agendador antes da execução do processo automático. Caso não seja
definida nenhuma abrangência para as tabelas de feriados, todos os feriados cadastrados
serão considerados.
No entanto, para que esta funcionalidade seja aplicada pelo Agendador, é necessário que
o processo automático referencie a localidade que possui a abrangência de feriados.
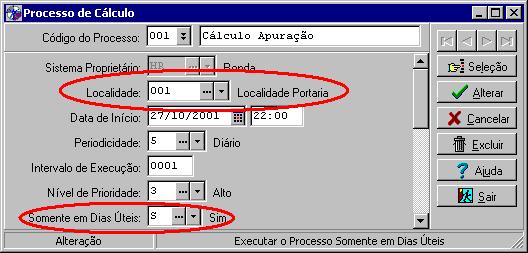
Para o cadastramento dos processos
automáticos a indicação da localidade não é obrigatória, sendo que no caso da não
informação da mesma, a verificação do dia útil considerará todos os feriados
cadastrados na base de dados.
A mesma idéia pode ser aplicada com relação à divisão dos processos por localidades.
Vamos voltar ao nosso exemplo anterior e suponhamos que exista um processo automático que
não teve sua localidade definida (o campo foi zerado). Isto significa que este processo
será executado tanto pelo Agendador em servapl, como pelo Agendador em servoff. Devido à
esta característica é importante que todos os processos tenham suas localidades
definidas caso o cliente tenha uma formação parecida com a do exemplo ou decida
utilizar-se do cadastramento de localidades.
A aplicação do cadastro de localidade para os processos automáticos
estende-se até este ponto. No entanto, as Localidades possuem uma grande importância
quando o cliente possui replicação de dados com uma base corporativa centralizada.
Cadastro de Localidades (Replicação de Dados)
O cadastro de Localidades possui
importância crucial para a configuração adequada do processo de replicação de dados.
Através das Localidades poderá ser configurado o fluxo dos dados a serem replicados para
as unidades que compõem a rede de replicação. Poderão ser definidas as unidades que
receberão colaboradores, ou colaboradores de outras unidades ou poderá ser limitada a
distribuição da informação.
Para permitir estas configurações adicionais, o aplicativo Replica utiliza-se das demais
informações da tela de cadastro de localidades, conforme segue:
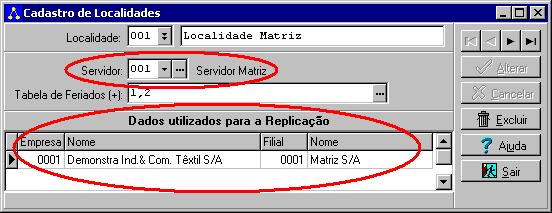
O código do servidor será utilizado para informar ao aplicativo
Replica qual será o servidor que conterá as informações da localidade específica.
Desta forma, quando as configurações forem efetuadas e a replicação foi iniciada, os
dados serão enviados para os servidores destinados (normalmente cada servidor possui uma
base de dados preparada para receber os dados enviados pela replicação).
A grade com o cadastro das empresas somente será utilizada pela
Replicação e indica quais são as empresas/filiais que estão contidas em uma
determinada localidade. Para efeito de entendimento, pode-se adotar que uma localidade
seja uma unidade física da empresa (prédio). Por exemplo, no prédio da matriz estão
presentes a empresa 1 e filial 1.
Desta forma a Localidade Matriz
compreende este conjunto de empresas. Para uma outra localidade, por exemplo, poderão
existir mais de uma empresa ou filial cadastradas. Teoricamente o termo
localidade pode assumir qualquer função, desde representação de um espaço
físico como a representação do organograma da empresa. Toda a definição dependerá do
uso e da intenção do usuário mediante o cadastramento.
Normalmente serão necessárias tantas localidades quantos servidores
de dados cadastrados, pois normalmente todas as informações pertinentes à uma
determinada unidade (localidade) estarão presentes neste servidor. No entanto, nada
impedirá do usuário efetuar uma configuração diferenciada para um mesmo servidor,
cadastrando mais de uma localidade para o mesmo com empresas/filiais diferentes, no
intuito de alterar o fluxo de informações utilizadas por estas empresas.
Para exemplificar a utilização do cadastro de localidade no
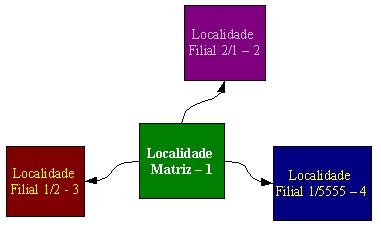
aplicativo Replica, utilizaremos o seguinte cadastro de localidades, conforme a Lista 1:
| Localidade | Descrição | Servidor |
| 1 | Localidade Matriz | 1 |
| 2 | Localidade Filial 2 / 1 | 2 |
| 3 | Localidade Filial 1 / 2 | 3 |
| 4 | Localidade Filial 1 / 5555 | 4 |
Para cada localidade, existe uma empresa/filial cadastrada conforme a Lista 2 a seguir:
| Localidade | Empresa | Filial |
| 1 | 1 | 1 |
| 2 | 2 | 1 |
| 3 | 1 | 2 |
| 4 | 1 | 5555 |
Com a Lista 1 podemos visualizar que todas as localidades estão apontando para diferentes servidores. Neste caso específico houve a coincidência de que todas as localidades possuem um servidor diferente.
Fluxo da Informação
Levando em consideração a cadastramento efetuado anteriormente para as localidades, dividindo as empresas/filiais em unidades distintas, foi levantada uma lista de necessidades a serem atendidas para o fluxo da informação que deverá ser respeitado pela Replicação de Dados, conforme segue:
- A empresa 1/1 deverá replicar seus colaboradores como colaboradores de outras unidades para as empresas 2/1 e 1/2. Para as demais empresas (1/5555) os registros de colaboradores serão replicados como tal.
- A empresa 2/1 deverá replicar seus colaboradores como colaboradores de outras unidades para a empresa 1/5555. Para as demais empresas os colaboradores serão replicados como tal.
- A empresa 1/2 deverá replicar seus colaboradores para a empresa 2/1 como colaboradores de outras unidades. Para as demais empresas não deverá replicar seus colaboradores.
A empresa 1/5555 não deverá replicar seus colaboradores para as demais empresas.
Para atender à estes requisitos de fluxo da informação da replicação deste exemplo, teremos que agrupar as empresas na forma de localidades e configurá-las na tela de Definição do Fluxo de Informação. No nosso exemplo, imaginaremos que a empresa possui a seguinte configuração regional, sendo que cada localidade correponde a uma localidade física e a localidade matriz possui uma base corporativa centralizada:
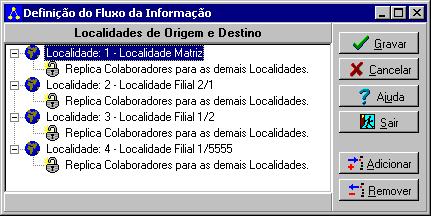
A primeira vez que a tela de Definição do Fluxo da
Informação for aberta pelo usuário, após o cadastramento de todas as
localidades, estas serão exibidas para que a configuração seja definida. O estado
inicial de cada localidade seguirá a definição padrão da replicação que não impõe
restrições para o envio das informações, isto é, todos os colaboradores daquela
localidade serão replicados como tal para todas as demais localidades, conforme
exemplificado na figura a seguir:
Desta forma, para configurar o Fluxo da Informação, temos que
adicionar as localidades necessárias para cada localidade exibida pela tela. Deve-se
notar que o padrão é replicar os colaboradores para todas as demais unidades.
Então, com a localidade 1 selecionada, deve-se clicar no botão
Adicionar. Será exibida uma lista das localidades que ainda não foram
incluídas na configuração, conforme a figura a seguir:
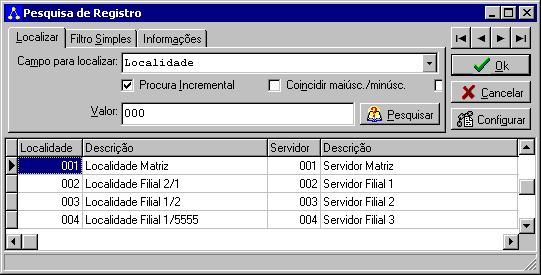
Como pode ser observado, as localidades
exibidas são todas as localidades cadastradas que ainda não foram utilizadas para a
configuração do fluxo da informação. É exibida inclusive a localidade 1, que é a
localidade selecionada.
Para efeitos de explicação, definiremos como RECEBEDORA a localidade
na qual estamos adicionando ou removendo localidades e definiremos como ADICIONADA a
localidade que será incluída ou excluída na configuração da RECEBEDORA. Desta forma,
para cada localidade que for utilizada na definição do fluxo da informação é feita a
seguinte verificação pelo sistema:
- Se a ADICIONADA for diferente da RECEBEDORA, esta será considerada
como receptora da replicação dos colaboradores como colaboradores de outras unidades.
Isto é, todos os colaboradores cadastrados nas empresas/filiais representadas pela
RECEBEDORA serão replicados como colaboradores de Outras Unidades para a localidade
ADICIONADA, conforme o código do servidor especificado na mesma (R034FUN => R070OCR).
- Se a ADICIONADA for a mesma localidade que a RECEBEDORA, significa que
os colaboradores (R034FUN => R034FUN) representados por esta localidade não serão
replicados como tal para as demais localidades cadastradas.
- Caso a RECEBEDORA não possua um registro indicando que o fluxo da
informação pára em si mesma, os registros de colaboradores serão replicados para as
demais localidades que não fizeram parte da definição do fluxo da informação.
Voltemos à lista de necessidades do fluxo da informação apresentada
anteriormente e selecionemos o primeiro item da lista: A empresa 1/1 deverá
replicar seus colaboradores como colaboradores de outras unidades para as empresas 2/1 e
1/2. Para as demais empresas (1/5555) os registros de colaboradores serão replicados como
tal.
Isto significa que serão adicionadas a Localidade 2 e
Localidade 3 na Localidade 1 , para que os colaboradores da
Localidade 1 sejam replicados como Colaboradores de Outras Unidades para estas
2 localidades. Para a Localidade 4 os colaboradores da Localidade
1 serão replicados como Colaboradores mesmo, não como Outras Unidades. Caso não
fosse desejada a replicação de colaboradores para a Localidade 4, bastaria
que fosse adicionada a Localidade 1 na Localidade 1. Adicionando a
localidade nela mesma, impedirá que os colaboradores representados por esta localidade
sejam replicados como tal para as demais localidades que não fizeram parte da definição
do fluxo de informação da Localidade 1.
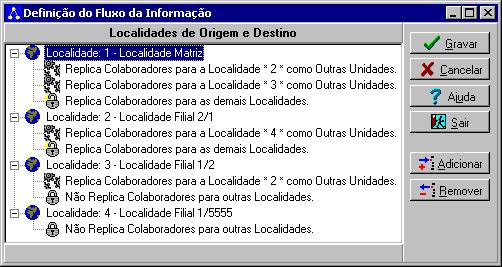
Legenda:
![]() -
Representa a localidade cadastrada.
-
Representa a localidade cadastrada.![]() - Representa a localidade que receberá os colaboradores
como colaboradores de outras unidades.
- Representa a localidade que receberá os colaboradores
como colaboradores de outras unidades.![]() - Informa que os colaboradores da localidade serão
replicados como colaboradores para todas as outras unidades.
- Informa que os colaboradores da localidade serão
replicados como colaboradores para todas as outras unidades.![]() - Informa que os colaboradores da localidade não
serão replicados para nenhuma outra localidade exceto a mesma.
- Informa que os colaboradores da localidade não
serão replicados para nenhuma outra localidade exceto a mesma.
 English
English Español
Español

